Oracle Cloud Monitering 親コンパートメントのアラーム定義は子コンパートメントのインスタンスに有効なのか
何を知りたいかと言うと、タイトルそのままです
「親コンパートメントのアラーム設定は子コンパートメントのインスタンスに有効なのか」
親コンパートメントで定義したアラーム定義が
子コンパートメント内のインスタンスにも適用されているかどうか。が知りたいのです
これが可能であれば、汎用化したい設定(例えばCPUが90%を超えたらアラート通知を出す)は、一番親にだけアラーム定義しておけばその配下の子コンパートメントで同じ設定を何度も繰り返さずにすみますよね。

アラーム定義は別の記事でたくさんナレッジが記載されているので、ここでは割愛し、アラーム定義は出来てることとします。 そして、以上があればメール通知がくるような設定になっております。
結果からするとできませんでした。
 そもそも親コンパートメントを選んでる時点で子コンパートメント内のリソースは表示されてないし、通常のメトリックでもみれてないし、
だからダメでした。
おそらく、コンパートメントはそもそもリソースへのアクセス権限を分けるのに有効な機能なので、リソースのアクセスはできるけど、アラート設定まで権限が及んでるわけではないのではないか。
そもそも親コンパートメントを選んでる時点で子コンパートメント内のリソースは表示されてないし、通常のメトリックでもみれてないし、
だからダメでした。
おそらく、コンパートメントはそもそもリソースへのアクセス権限を分けるのに有効な機能なので、リソースのアクセスはできるけど、アラート設定まで権限が及んでるわけではないのではないか。
んー、もしできた人がいれば是非教えてほしいです。
OracleAnalyticsCloudをコマンドで起動停止する方法 psm setupまでにめっちゃてこずった
- pythonバージョンが3.3以下であればインストールする
- python3インストール
Red Hatおよびそれから派生した OS では、yum を使用します。yum リポジトリで、使用可能な Pythonのバージョンを確認します。次に、正しいパッケージ名に置き換えて次のようなコマンドを実行します。 $ sudo yum install python36- Oracle CloudコンソールからのCLIのダウンロード
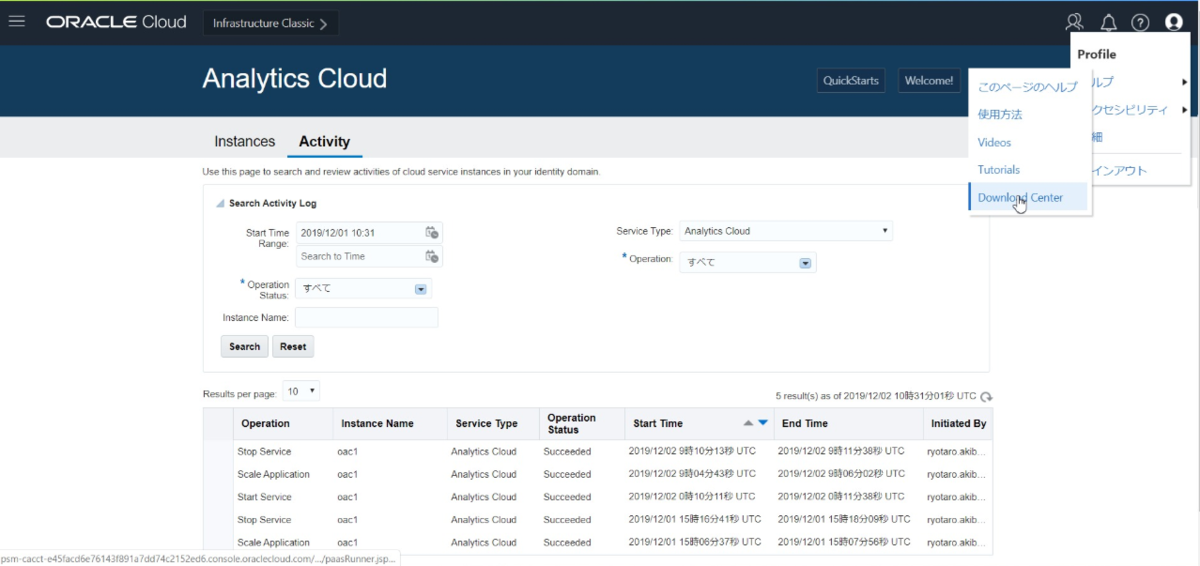
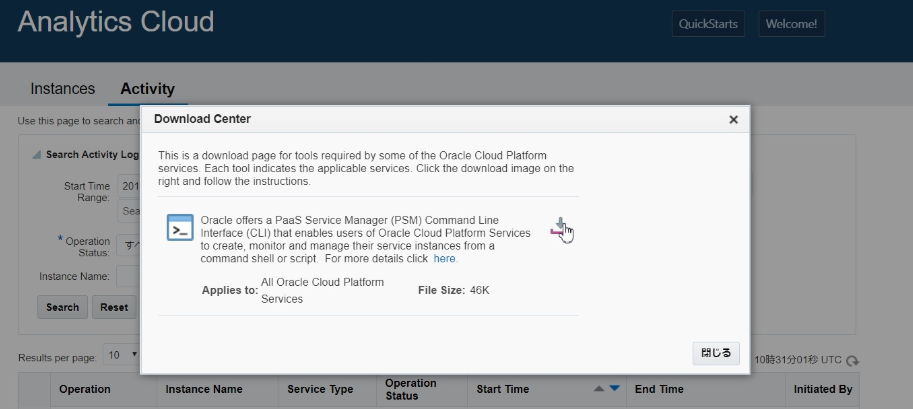
DLしたファイルをWinSCPを使って
Linuxサーバ上に配置しておく。
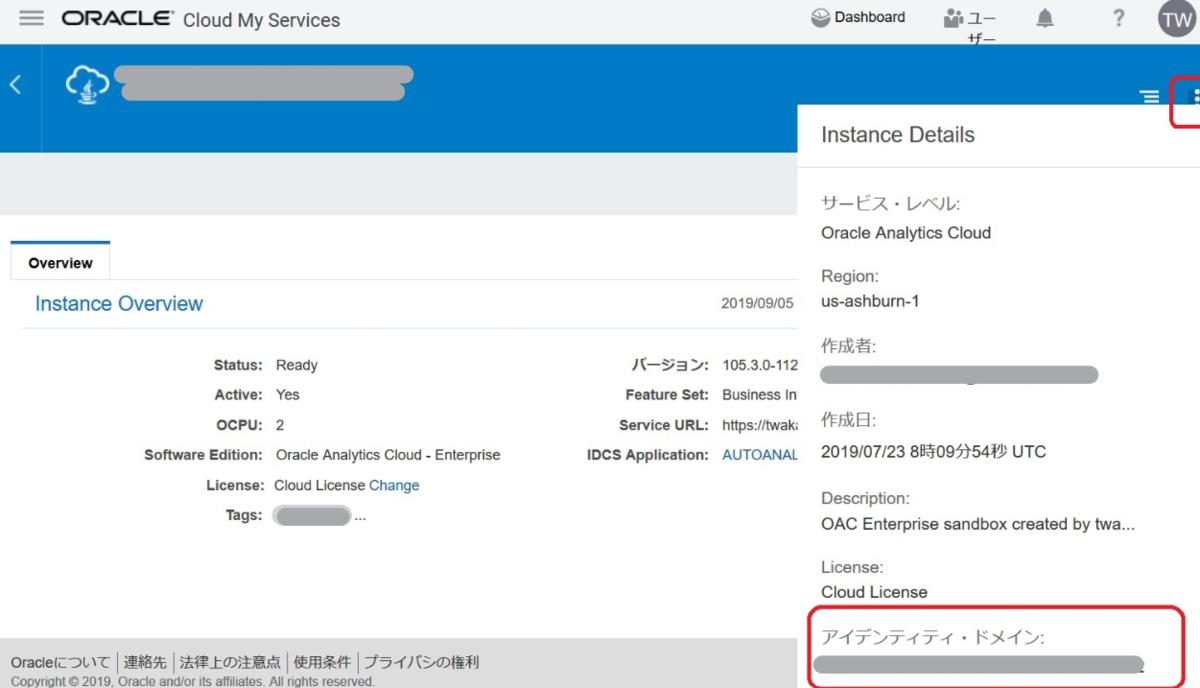
アイデンティティドメインを確認する
テラタームでアクセスしpsmcli.zipがあることを確認し curlでpsmcli.zipに書き込む設定をする
curl -X GET -u [ユーザ名]:[パスワード] -H
[テナント名]:idcs-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX https://psm.us.oraclecloud.com/paas/api/v1.1/cli/idcs-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX/client -o psmcli.zip
(curl -X GET -u myuser321:password -H X-ID-TENANT-NAME:MyIdentityDomain54321 https://psm.us.oraclecloud.com/paas/api/v1.1/cli/MyIdentityDomain54321/client -o psmcli.zip
)
psmをインストールする
sudo -H pip3 install -U psmcli.zip
psmセットアップ
[opc@shiseido-instance ~]$ psm setup Username: [ユーザ名] Password: Retype Password: Identity domain: idcs-XXXXXXXXXXXXXXXXXXXXXXXXXX Region [us]: Output format [short]: Use OAuth? [n]:
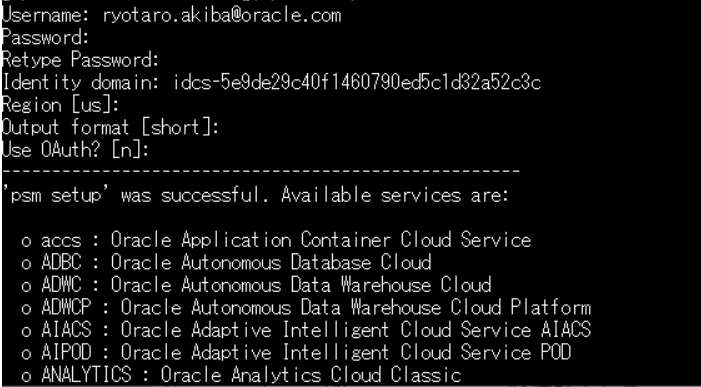 CLIがOracle Cloudに正常に接続すると、このクラウド・アカウントで利用可能なサービスが一覧表示されます。(↑みたいに)
CLIがOracle Cloudに正常に接続すると、このクラウド・アカウントで利用可能なサービスが一覧表示されます。(↑みたいに)
ここまできたらpsmコマンドが打てるので
psm AUTOANALYTICSINST stop-service -s
止めてみる
[opc@shiseido-instance ~]$ psm AUTOANALYTICSINST stop-service -s oac1 Message: Job submitted successfully for stop of service/system Job ID: 155545347
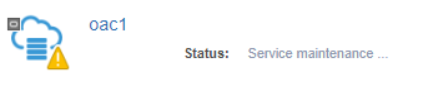
起動してみる
[opc@shiseido-instance ~]$ psm AUTOANALYTICSINST start-service -s oac1 Message: Job submitted successfully for start of service/system Job ID: 155670706 問題なくいけました。
【意外と難しい!?】G検定に合格日誌
合格したので覚えている範囲で書き残します
はじめに感想を少し。 200問あって前半悩みすぎて後半テキトー回答多しで 正直全然自信なかったですが、合格でしたw 今回受験料半額ということもあり受験者が過去最多で、12000人うけて8000人くらい受かってるから落ちる方が少数派というね。 一体全体何点以上が合格で、自分は何点だったのかが確認出来ないのがもどかしい。(←公表されないようです。。なんだかなぁ) ちなみに私が勉強に使ったのはこの1冊だけ。あとはネットでググった情報ばかりです。

この本だけで十分だったかと言えば、合格はしたものの決して十分ではなかった。 結構カバーできてない領域あるなーと思いながら問題を解いてました。 問題を解いてる最中に調べたりすることは許容されているので、何個か調べたり本見返したりはしましたが、 これをやっていると確実に時間が足りなくなります。
では実際にどんな問題が出たのか。
法律とか知的財産問題がたくさん出ててこずった
・オープンデータを基にして作成されたモデルには著作権があるの?とかどこの範囲まで著作権がおよぶの?みたいない問題
・AIのために新たに作られた法律とか、ドローンに関する法律も出題された
→正直この辺まったく本では勉強していなかった範囲です。こんな感じの問題が前半続いたため焦りました。 AI白書読めばこの辺書いてたのかなぁ。。。
アルゴリズム
・サポートベクターマシーン
・ランダムフォレスト
・決定木
まぁこの辺の教科書にかいてあるようなことは当然でました。
AIの歴史問題も結構多い
・何次ブームの特徴とうまくいかなかった原因とか
・開発されたAIの順番を答える問題とか。
まぁこの辺も教科書通りでしたね、うる覚えばっかりで危うかったけどw
このテキストだけでは網羅できてない範囲が多かった
このテキストを素早く2周してうる覚え状態で挑みましたが、「あー何か書いてあったな」って問題ももちろん多いのですが、意外だったのが、「なにこれ?全く初見初耳ですよこんな問題、こんな人名」みたいな問題も多かったです。正直さっぱりわからない問題が前半に続き、だいぶ精神面でやられました。
ここから先は学習に使ったキーワード集です。
基本的にG検定はキーワードを聞いて、それが何かをざっくり説明できれば良い。という問題なので キーワードだけ集めました。一つ一つの意味とかわからなければ自分で調べて答えられるようにしておくと良いでしょう。
人口知能とは
- 明確な定義がない
- 第1次AIブーム:推論や探索、1950年代〜1960年代
- 探索木
- ダートマス会議
- 問題点:トイプロブレム(簡単な迷路やパズルなどの限定されたもの)しか解けない
- 第2次AIブーム:知識表現、エキスパートシステム、1980年代
- エキスパートシステム
- 問題点:常識など広い範囲の知識をちくせきするのが膨大で困難
- 第3次AIブーム:機械学習と深層学習、2010年代
- ムーアの法則でCPUが進化し、深層学習が登場
人口知能をめぐる動向
- ムーアの法則でCPUが進化し、深層学習が登場
- 探索と推論
- 探索木 ハノイの塔
- ブルートフォース 力任せに多数のシミュレーションを計算する探索法
- ボードゲームで人間に勝つ
- DeepMind社のAlphaGoが2015年に将棋で勝利
- 2017年にはAlphaGo Zeroが登場
- 知識表現
- 対話システム(イライザ) あたかも対話しているかのよう
- エキスパートシステム 専門知識を詰め込んだが、データの蓄積・管理が膨大なことが問題に
- 意味ネットワーク(Cycプロジェクト) 今もなお30年以上続いているプロジェクトで一般常識を全部詰め込んでやりたい強い気持ち
- IBMのワトソン
- 機械学習
- 深層学習
- ディープニューラルネットワーク(DN) 単純パーセプトロンという一番シンプルな構造が複数組み合わさり、入力層と出力層の間に隠れ層が多数存在するものをDNNという。
特徴量を自動で学習 ジェフリーヒントン教授がILSVRC その後、AlexNet、ResNet、Kaggle
ILSVRC、AlexNet、ResNet ImageNet Large Scale Visual Recognition Challenge ImageNetという大規模な画像データセットを用いた一般物体認識のコンペティション。
人工知能分野の問題
- トイプロブレム 簡単なルールがあるおもちゃ問題しか解けない
- モラベックのパラドックス 数式が解けたとしても、実は人間が無意識になっている認識や運動を実現することこそが非常に難しいよ
- チューリングテスト チューリングさんが言った、チャットして相手がコンピューターと見抜けなければ知能があるとする判定方法。イライザが話題に。
- 強いAI、弱いAI 哲学者ジョン・サール 心を持つ汎用AIが強いAI,持たなければ弱いAI。 一見会話が成立しているように見えても実は意味を理解していないんじゃあかんやろ
- 知識獲得のボトルネック Cycプロジェクトのこと、膨大なコストと時間がかかる
- フレーム問題 「今解こうとしている問題に関係のあることだけを呼び出す」ことが難しいという問題。 「ロボットが時限爆弾を上に乗せたバッテリーを洞窟の中から運び出す」というのが例。
- シンボルグラウンディング問題(記号接地問題) 「しま」の意味と「馬」の意味を理解し、初めてシマウマを見たときに「アレガ、シマウマか」と理解することが難しいという問題
- 特徴量設計 適切な特徴量を抽出することが重要であり、知見ナレッジ経験が必要な職人技になるかも
- ノーフリーランチ定理 どんな問題に対しても万能な汎用アルゴリズムなんて無い。という定理
- シンギュラリティ(技術的特異点)
2045年、コンピューターが人間を上回る年、ここが特異点です。
確率統計
確率
- 自己情報量 ある事象が起きたと知ることでどれだけの情報量が得られるのか。を数値化したもの。 確率が小さい事象ほど、実際に起きたことを知ることで得られる情報量は大きい。 各自に起きる事象を知ったとしても得られる情報量はゼロ。
- エントロピー 熱力学の言葉でもある。事象が起きたと知ることによって、平均どれだけの情報量を得られるか。を数値化したもの。 事象の起こる確率と自己情報量を掛け合わせたものの総和。で求める。 全ての事象が等確率のときエントロピーは最大をとる。
- 相互情報量 2つの確率変数がどの程度関連を持つのか。を数値化したもの。 つまり、相互情報量は不確実性(エントロピー)の減少量とみなすことができる。
- 交差エントロピー 2つの確率分布がどれくらい離れているか。を数値化したもの。 交差エントロピーが小さくなるように学習をしてモデルの制度をあげるわけ。
行列、線形代数
機械学習
教師あり
回帰問題と分類問題がある。 - 線形回帰 - ロジスティック回帰 ・二値分類ロジスティックでは、シグモイド関数で出力値が0〜1に収まるように正規化する。 ・多項分類ロジスティックでは、ソフトマックス関数で出力値が合計で1になるように正規化する。 ・説明変数の重みの算出に尤度関数を用いる - サポートベクターマシン(SVM) ・マージンを最大化することで最適な境界線を引く。 ・マージンとは学習データのうち最も決定境界線に近い点と境界線との距離。 ・例外データを許さない線引きをハードマージン、許容するのをソフトマージンと呼ぶ。 ・ソフトマージンにおいて誤分類を寛容するためにスラック変数というものを使う。 ・非線形の境界線はカーネル法と呼ばれる。 ・カーネル法のサポートベクターマシン、このカーネル法の計算量を削減する方法をカーネルトリックという。 - 決定木 ・条件分岐で分類していく ・情報利得の最大化という考え。 - ランダムフォレスト - アンサンブル学習 ・性能の低い学習器を組み合わせて高性能の学習器を作る方法。 ・バギングとブースティングがある。 ・バギングとは弱学習器を並列に組み合わせる方法。 ・バギングの代表例がランダムフォレスト。 ・ブースティングは並列ではなくて直列に組み合わせていく方法。 ・ブースティングの代表例が勾配ブースティング。 - 勾配ブースティング - ベイジアン学習 ・条件付き確率を利用した機械学習アルゴリズム。 ・結果から原因を推論する。 ・スパムメールフィルターやレコメンデーション機能につかわれる。 ・ベイズの定理。事象Bが起こった時に条件Aであった事前確率P(A|B)を推算する式。 ・尤度(ゆうど)、最もらしさの指標。ロナルドフィッシャー。 - ナイーブベイズ ・シンプルで処理が高速。文書分類やスパムフィルタに使われうる。 - k近傍法(k-NN法) ・クラスタリング ・あらかじめクラス分けされた教師データを元に、新しいデータが入ってきた時に、最も近いk個データのクラスから多数決で分類する方法。 - 時系列分析 - 自己相関 ・過去の地震の変数と相関関係にあるもの。その相関係数を自己相関係数という。ラグhの自己相関とかいう。 - 定常性 - MA(Moving Average)(移動平均)モデル ・ホワイドノイズとラグ1のホワイドノイズに重みづけしたもの。 - AR(Autoregressive:自己回帰)モデル - ARMAモデル ・MAモデルとARモデルを組み合わせた - ARIMAモデル(自己回帰和分移動平均) ・ARMAに加えて時系列の階差もつかう。 - 単位根過程 ・非定常性&わかりにくい時系列データ - クラスタリング
教師なし
- 次元削減 ・より少ない次元でデータを理解する
- 主成分分析(Primar- y Component Analysis) ・一番正の相関がある方向を第一主成分軸とし、それと垂直の方向を第2主成分とする。 ・第一主成分軸を回転させ、x軸となるように回転させ、その状況において、第二主成分軸をy=0(つまりx軸上)に落とす。これによって次元圧縮ができ計算が早くなる。 ・主成分分析の結果は主成分の清戸を表す主成分得点(スコア)と、観測変数との相関性を表す主成分負荷量で評価できる。
- t-SNE法 これも高次元データを次元圧縮する手法 ・t:t分布 ・S:確率的 ・N:隣接 ・E:埋め込み
- クラスタリング
・対象データを幾つかのクラスタに分類する
・k−means法
・データをk個のクラスタに分類し、各クラスタの重心に一番近い点をそのクラスの代表ということにして、どんどんデータ代表を作り出すことでデータを減らして計算を早くできる。
・データの凝集でシルエット法ともいう。しデータを減らすことはエルボー法ともいう。
半教師あり
強化学習
エージェントがより高いゲームスコア(報酬)を得るために何度もなんども挑戦する。
前処理
- 正規化 データの値が0~1などの指定範囲に収まるように加工する。 画像処理における色の濃さを調整する処理などがある。
- 標準化 データの平均が0、分散が1になるように、値を加工する
- ハイパーパラメータ 学習における初期値やモデルのニューロン数など、学習に影響する学習前に決めておく値。
- バッチサイズ 1000件のデータセットを200件ずつのデータセットに分けた場合、バッチサイズは200となる。 200件の学習を5回できるので、この場合、イテレーション数は5となる。 すべての訓練データを学習すると1エポックとなる。
- 汎化誤差 ・未知のデータに対する予測と実際の差。 ・バイアス、バリアンス、ノイズの3要素になる。 ・バイアスは、予測モデルと学習データとの差の平均を数値化したもの。予測モデルが単純すぎるとどんどんずれが大きくなっていく。 ・バリアンスはその逆で、モデルが複雑すぎて汎化できてないモデル。 ・ノイズは、削除不能な誤差、余計なデータが混ざってる。
- 誤差関数
正解ラベルと予想の近さを評価します。
ディープラーニングの特徴
- ニューラルネットワーク ・事前に特徴量を設定せずとも、学習しながら特徴量を得ることができる。
- 近似
- 内部表現 ・観測データから本質的な情報を抽出した特徴のこと。
- エンドツーエンド学習 ・ニューラルネットワークは特徴量の設計とその後の処理をまとめて自動的に行うE2E学習雨ができるようになった。
多層パーセプトロン
ニューラルネットワークの最も基本的なもの。 層状にユニットニューロンが並んでいて隣接層間のみで結合している。あの形 - 重み $$w_n$$ - バイアス $$b$$ - 活性化関数 $$f(u)$$ 各出力x1,x2,x3,x4とある時、それぞれに重みw1,w2,w3,w4をかけたものの総和に、 バイアスbを足した値uを求める。 そしてこのuが活性化関数fによって変換されて、次の層ユニットへの入力zになる。 $$u=w_1x_1+w_2x_2+w_3x_3+w_4x_4+b $$ $$z=f(u) $$
出力層の活性化関数
- 単純パーセプトロン
- ステップ関数
- 回帰
- 恒等関数
- 他クラス分類
- ソフトマックス関数
中間層の活性化関数
OracleCloud WAFの説明
まずはWAFの課金体系
クラウドなので、基本亭には使った分だけ課金されます。 課金対象は下記の3パターンなのでいろいろWAFポリシーを多く設定すればするほど課金も高くなってきます。とはいえ、自分のサーバが従来どのくらい攻撃されてたかなんて把握してない人が多いので、実際は毎月試しながら、どのくらいのリクエスト量なのかBOT検知してるのか、などを見ていけばいいと思います。
オラクルクラウドサービスの中のWAF(Web Application Firewall)は種類が3つあります。
- WAF 1,000,000 incomingリクエスト
入ってこようとしたリクエスト全部に対してチェックする
- WAF GB of Good Traffic
上のチェックに加えて、通過させた分のトラフィック量に足しても課金が発生する
ボットのチェックは別料金となって、高額な単価で課金がかかる。 この機能を使うかどうかは選べるはず。
ボット対策とは:インターネット上では、ボットによるトラフィックは人間によるそれよりも多くなっています。ボットの大半は悪意のないものですが、しかしそれゆえ単にボットを全てブロックしてしまうということもできません。JavaScriptチャレンジ、CAPTCHAチャレンジ、ホワイトリスト機能をWAFルールセットと併せて用いることで、良性ボットをとおして悪性ボットをブロックすることが可能です。
そもそもOCI WAFの機能の整理
端的にまとめるとこの5つくらいです。 ホワイトペーパーを見てみると他にもインテリジェンスチームが24時間体制で監視してまっせみたいなことも書いてあるけど、機能っぽくないので却下しましたw
- 250 を超える定義済みのルール 250以上のルールセットとOWASPルールセットをサポートし、SQLインジェクション、クロスサイトスクリプティング、HTMLインジェクションなどの脅威から保護します。
- BOT 検知 JavaScript、CAPTCHA、ホワイトライティング機能により、悪意あるボットを検出し、トラフィックへのアクセスを制御します。
- IP アドレスによるホワイトリスト・ブラックリスト制御 国、IPアドレス、URL、およびその他の要求属性に基づいてユーザーアクセス制御を構成し、危険なトラフィックを禁止できます。
- オンプレミス、マルチクラウド環境を保護 あらゆる環境において(OCI、オンプレミス、マルチクラウド)、インターネットに接続するすべてのアプリケーションを保護できます。
- API や SDK を用いて管理できる すべての操作に対してAPI、SDK、Terraformをサポートしており、他のOCIサービスと統合できます。
基本動作としては、
まずWAFを作る前に外部公開用のDNSレコードを作成しておき 、それを守りたいwebサーバのCNAMEとしてDNSに登録することで、トラフィックをWAF経由に設定することができる
 WAFを作成したら
WAFポリシーやBOT検知をするかどうかの設定を追加していきます。
WAFを作成しても何もポリシーの設定をしなければ、ザル状態で言わば課金もされません。何も検知しないから。
オラクルが事前に準備している250以上のルール(ポリシー)はオンオフを選ぶだけで適用できるようになっています。
ちなみにこれらの250といってるルールはOWASPのTOP10に挙げられているようなリスクに対応できるようにと設計されている。らしい
https://owasp.org/www-project-top-ten/?gclid=EAIaIQobChMIiJu7t4v76AIV8Z7CCh1xbgcCEAAYASABEgLOWPD_BwE
WAFを作成したら
WAFポリシーやBOT検知をするかどうかの設定を追加していきます。
WAFを作成しても何もポリシーの設定をしなければ、ザル状態で言わば課金もされません。何も検知しないから。
オラクルが事前に準備している250以上のルール(ポリシー)はオンオフを選ぶだけで適用できるようになっています。
ちなみにこれらの250といってるルールはOWASPのTOP10に挙げられているようなリスクに対応できるようにと設計されている。らしい
https://owasp.org/www-project-top-ten/?gclid=EAIaIQobChMIiJu7t4v76AIV8Z7CCh1xbgcCEAAYASABEgLOWPD_BwE
WAFで防御できる攻撃の例
オワスプTOP10って何よ?てかWAFで具体的にどんな攻撃防げるの?と言われたら 一旦下記で答えよう。オワスプ10にはもっともっと載ってるが、具体的な攻撃名とかでない項目もあるので、皆がイメージしやすいのはこんな感じかなと。 DDoS攻撃 ボット攻撃 SQLインジェクション HTMLインジェクション クロスサイトスクリプティング など
WAF設定方法
オラクルが出しているチュートリアルを見ると設定の仕方が分かりやすく乗っている https://community.oracle.com/docs/DOC-1030654
最後にOCIWAFの情報はなかなか少ないのでホワイトペーパーを見ておくこともおススメだ https://www.oracle.com/jp/a/ocom/docs/oracle-cloud-infrastructure-waf-data-sheet.pdf
【Oracle Cloud Infrastructure】windowsインスタンスにブロックボリュームをアタッチする
なかなかドキュメントはわかりづらいのでメモメモ やることはカンタンにまとめると
一応ドキュメントはこれね https://docs.oracle.com/cd/E97706_01/Content/GSG/Tasks/addingstorageForWindows.htm
1.2は余裕でできるので省略、アタッチのところから解説します
インスタンスで下の方を見ると「アタッチされたブロックボリューム」があるのでクリック

ブロックボリュームのアタッチをクリック

アタッチするボリュームを選択し、それ以外はデフォルトのままでOK、そのまま「アタッチ」をクリック

下記画面になり、1分くらいするとアタッチが完了する

右側にある点3つのアイコンクリックし、「iSCSIコマンドおよび情報」をクリック

するとIPなどの情報が出てきます。 ここのIPとポート情報は後ほど使うのでメモしておく。

windowsインスタンスにRDPで接続するためVCNのセキュリティリストにRDPのポート許可をしておくことをお忘れなく。 個の設定方法は別途情報いろいろでてるので、ここでは省略します。

RDP接続
WindowsサーバにRDP接続したら サーバーマネージャーを開き「ツール」から「iSCSIイニシエーター」をクリック
 検出タブから「ポータルを検出」をクリック
検出タブから「ポータルを検出」をクリック
 先ほどメモしたブロックボリュームのIPとポートを入力し「OK」をクリック
先ほどメモしたブロックボリュームのIPとポートを入力し「OK」をクリック

ターゲットタブを開くと「検出されたターゲット」に表示されたブロックボリュームを選択し、「接続」をクリック

そのまま「OK」をクリック

サーバーマネージャーの「サーバ」>「ディスク」を確認するとアタッチしたブロックボリュームが確認できます。
 これをDドライブとかEドライブにするには、
ボリュームの中で右クリックし「新しいボリューム」を選びます
これをDドライブとかEドライブにするには、
ボリュームの中で右クリックし「新しいボリューム」を選びます
 そのまま「次へ」
そのまま「次へ」
 サーバとディスクで、先ほどアタッチしておいたディスクを選択し、「次へ」
をクリックすると確認がポップアップされますがそのまま「OK」
サーバとディスクで、先ほどアタッチしておいたディスクを選択し、「次へ」
をクリックすると確認がポップアップされますがそのまま「OK」
 ディスク容量のうち何GBを利用するか聞かれるので設定します。
ここでは2TBアタッチしたディスク全部をEドライブにするつもりなので
このまま「次へ」をクリック
ディスク容量のうち何GBを利用するか聞かれるので設定します。
ここでは2TBアタッチしたディスク全部をEドライブにするつもりなので
このまま「次へ」をクリック

何ドライブにするかを聞かれるので ここでは既にDドライブは作っているので、そのままEドライブとしちゃいます なので特に何も変えず「次へ」をクリック
 ファイルシステムの設定もそのまま「次へ」
最後に確認画面が表示されるので「作成」をクリックします
ファイルシステムの設定もそのまま「次へ」
最後に確認画面が表示されるので「作成」をクリックします


すべて完了したら、「閉じる」をクリック
すると このようにEドライブとしてエクスプローラーに表示されるようになりました

以上!!!
Oracle Analytics Cloudの数値予測のトレーニングの理解
Oracle Analytics Cloud(OAC)のデータフローで取り込んだデータに対して
トレーニングモデルを作成したい際にはこんな感じでやっていきますが


数値予測のトレーニングの項目を見ると
英語だしなんだか分かりづらいのでここで解説します。

Target
これは簡単で、モデルを作りたい項目はどれかを選べばいいだけです。
Regression Method
回帰の種類を選択します。
- Lasso回帰
- リッジ回帰
- Ordinary Least Squares(最小二乗回帰)
Regularization Weight
正則化の重みを1~100で選びます。
Regularization Weight(L1 ratio or L2ratio)
Please enter 0 if it is ordinary least squares linear regression
Categorical Column Imputation
属性データにおいて、もしNA(該当なし)のデータが出たときに
一番頻出する値を代入するのか一番頻出しない値か。
デフォルトでは最多頻出値となってます。
- Most frequent
- Least frequent
the mode method for categorical features to fill NA.
Two options: most frequent and least frequent .
default is most frequent.
Numerical Column Imputation
数値データにおいて、もしNA(該当なし)のデータが出たときに
平均値か最大値か最小値か中央値どれを代入するか。
-Mean
-Maximum
-Minimum
-Median
Categorical Encoding Method
カテゴリ変数のエンコーディング
(文字列を数値として持ち直す的な。例えば曜日で「日→0、月→1、、、」)
の手法を選択
Indexerエンコーディング
Onehotエンコーディング
Maximum Null Value Percent
Null値を最大何%許容するか
Train Partition Percent
読み込んだデータのうち、何割を学習に使うか。
Standardization
True
False
学習前に標準化するかしないか。する場合はTrue。
機械学習では学習する前に生データをスケーリングする場合が多々あります。
https://qiita.com/ttskng/items/2a33c1ca925e4501e609
オラクルクラウドだと予算オーバーしない3つ理由
クラウドに移行したら思ってた以上の請求書がきた!!
という声が多く上がっていました。
この原因は、従来オンプレでは全く気にしていなかった
データ転送量が原因です。
クラウドの転送量って?
クラウドでは、クラウドの中にデータを持ち込むのは基本タダですが、
クラウドからデータを引っ張ってくると有料になります。
例えば、業務ファイルダウンロード機能を持つシステムなんかの場合、1ユーザが1か月に1GB分のデータをクラウド上からダウンロードしたりすると、100人規模の会社では毎月100GBをクラウドから出したことになります。
例えば、これがAWSだと1GBあたり0.114ドル課金されるため
100GBで11.4ドルの請求が来てしまい、クラウド慣れしてない人達からすると
何じゃこりゃー!?
となってしまうのです。
オラクルクラウドだと予算オーバーしない3つ理由
オラクルクラウドでも、同じようなデータ転送量に対する課金は発生します。
しかし他のクラウドベンダーと違う特徴があります。
- 1つ目は10TB/月まで無料。結構ありがたいです。
- 2つ目は、超過したとしてもそもそも課金額が安いのです。先ほどAWSが1GBあたり114ドルに対して、1GBあたり0.0085ドルとなってます。
- 3つ目は、予算という機能があり、あらかじめ設定した金額に到達or到達しそうになったら通知メールを飛ばすという運用ができます。
オラクルクラウドではこのようにサービスごとにいくら使っているのかを確認できるようになってます


予算の設定ができる
予算を使用して、テナンシ内のコスト追跡できます。コンパートメントの予算を作成したら、予算の超過が予測される場合または支出が特定の金額を上回る場合に通知するアラートを設定できます。

こんな感じで予算ルールの作成をするだけです


いーじょう!